南方电网人工智能科技有限公司赵必美团队联合中国科学院声学研究所,在《网络新媒体技术》发表论文《电力行业知识性大语言模型构建方法研究》。该研究针对通用大语言模型存在的“幻觉”问题,结合电力行业知识实时更新、答案精度要求高的行业特点,提出一套完整的行业专用大语言模型构建方案,经实验验证,该方法可有效抑制模型错误输出,显著提升电力领域知识问答的准确率。
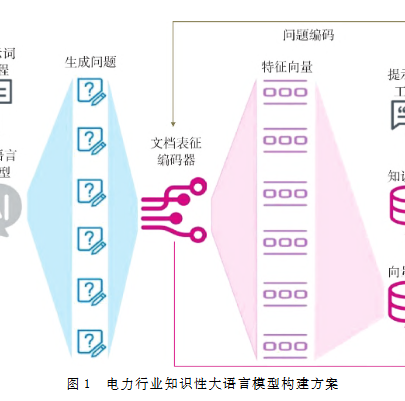
当前通用大语言模型依靠海量参数实现自然语言理解、逻辑推理与文本生成能力,但受限于训练模式,知识无法实时迭代,容易生成虚假、过时内容,也就是“幻觉”现象,难以直接应用于电力这类对专业性、准确性要求严苛的垂直行业。为此,研究团队依托检索增强生成(RAG)技术思路,搭建了全流程行业大模型构建体系,主要分为三大核心模块。
首先是电力行业外部知识库搭建,研究创新检索粒度对齐方法,统一多格式文档,借助大模型生成问答映射关系,解决文本切片与用户提问语义粒度不匹配的问题。其次优化文档表征编码器,以BERT为基础模型,结合电力行业问答语料、改写平行语料,采用负样本挖掘与迭代对比学习方式训练,强化模型对行业语义的识别能力。最后设计外部知识融合策略,拼接文档切片及上下文内容构建提示词,规避单一片段语义残缺问题。
研究选用Power-Know、Power-Cust两大电力实测数据集开展验证,以Baichuan-13B-Chat作为基座模型,在召回率多项指标上,本方案全面优于BGE系列主流基线模型,部分测试集召回率达到100%。实际案例测试显示,通用大模型回答电力巡检问题时易出现错误内容,而本模型结合外部知识库,可输出规范、准确的专业答案。
该成果完善了垂直领域大模型落地路径,不仅能为电力智能问答、客服咨询、现场运维等场景提供技术支撑,也为能源、制造等其他专业领域打造行业知识性大语言模型提供了可参考的技术范式。
转载请注明来自:http://www.lunwencheng.com/lwdt/22785.html
