摘要:随着大语言模型(LLM)的飞速发展,其在通用领域已经展现出强大的自然语言理解( NLU)、逻辑推理,以及自然语言生 成(NLG)等能力。然而,大语言模型的“幻觉”问题,使其在垂直领域( 例如,电力行业) 的应用受到了限制。本文以电力行业 为例,对构建该垂直行业知识性大语言模型的方法进行研究,提出一套完整的构建方案。该方案包含电力行业外部知识库构 建方法,电力行业文档表征编码器训练方法以及大模型外部知识融合方法。实验表明,该方案在减少大模型“ 幻觉” 现象,提 高行业知识性问答准确率中起到了重要作用。
关键词:大语言模型,电力行业,知识增强,信息检索,幻觉现象
论文《电力行业知识性大语言模型构建方法研究》发表在《网络新媒体技术》,版权归《网络新媒体技术》所有。本文来自网络平台,仅供参考。
0 引言
自2022 年OpenAI 发布了ChatGPT [1] 以来,大语言模型已经在通用领域展现出巨大的应用潜力,逐步将 自然语言处理领域的任务统一到一个序列到序列的处理范式。然而,大语言模型强大的能力,在很大程度
上建立在其巨大规模的参数上,这导致其训练需要消耗大量的计算资源与时间( 往往需要在大规模GPU 集 群上进行长时间训练)。因此,其在训练阶段学习到的“世界知识”信息无法实时地被更新,导致模型出现幻 觉的现象(生成过时或者虚假的信息) [2-4] 。
为了解决上述问题,检索增强语言模型技术(Retrieval Augmented Generation, RAG)被提出 [5-7] 。其核心 思想,就是将大模型与检索技术进行结合,借助外部知识库可以实时对知识进行更新与维护的优点,解决大模型的“幻觉”问题。大量的研究表明,这种结合模型内部“参数化” 知识与外部“ 非参数化” 知识的RAG 方 式,能够显著提升大模型生成过程的可解释性与可靠性。检索增强语言模型技术具体流程如下:
步骤1:利用输入大模型的原始问题,借助检索工具,从外部知识库中检索出与原始输入有关的知识;
步骤2:将检索到的外部相关知识与原始问题根据相应提示词工程( Prompt Engineering, PE) 方法转换 成输入大模型的提示词;
步骤3:将构建好的提示词输入大模型,显式地引导大模型的最终内容生成。
其中步骤1 检索到的外部知识,为大模型的后续内容生成提供具体依据,使大模型内容生成过程不仅 依赖模型的内部知识,从而有效地避免了模型“幻觉”现象的出现。
电力行业中,领域知识往往是实时更新的,并且对答案的准确率要求较高,因此,通用领域大语言模型 无法解决电力行业的知识性问答需求。
本文针对上述问题,围绕电力行业提出一个行业知识性模型的整体构建方案。该方案包含电力行业外 部知识库构建方法,电力行业文档表征编码器训练方法以及大模型外部知识融合3 个部分。
1 电力行业知识性大语言模型构建方案
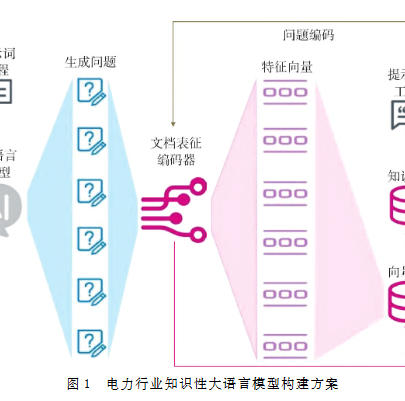
本节将从电力行业外部知识库构建,电力行业文档表征编码器训练以及大模型外部知识融合3 个角度 来介绍提出的构建方案。电力行业知识性大语言模型构建方案整体流程见图1。
1.1 电力行业外部知识库构建方法
在检索增强语言模型技术中,外部知识库构建是一个重要的步骤。知识库构建的质量与方式对后续外 部知识检索的准确性、可维护性以及灵活性都有较大的影响。
由于大语言模型只能接受纯文本格式的数据,因此构建电力行业外部知识库时,首先需要将不同来源, 格式不同的文档(例如:pdf 格式,docx 格式以及图片格式的文件) 转换成统一的结构化文档( 纯文本txt 格 式)。这一过程涉及到数据清洗以及初步的标注操作( 例如,对清洗过后较长文本进行人工切片操作)。
在得到结构化文档之后,针对这些文档建立索引以便后续的检索操作。现阶段,信息检索中建立的索 引主要分为稀疏检索索引 [8] 以及稠密检索索引
[9]2 大类。稀疏检索索引专注于提取出文档的浅层特征( 例 如,词频特征)。稀疏检索索引构建方法的代表是BM25 算法 [10] 。其使用的倒排索引结构具有响应速度快 的特点,因此BM25 成为一个被广泛用于工业界的检索工具。然而由于该类索引只关注文档的表层词特征, 因此其对于包含复杂语义相似性的场景效果表现不佳( 例如,同义异形词)。为了解决上述问题,稠密检 索索引构建技术被提出。该类方法以神经网络为工具,对文档的深层次语义特征进行编码提取。通常首先 训练一个文档表征向量编码器,然后利用该编码器将文档转换成固定维度的数值化向量并集中存储于专用 向量数据库,该过程如式(1)所示。
[Vec_{n}= Encoderleft( Doc _{n} ight) ag{1}]
其中 (Doc) 代表第n 个文档切片 (Vec) 为对应的数值化表征向量且 (V e c_{s}={v_{n 1}, v_{n 2}, cdots, v_{s d}}) , d 为编码的 表征向量维度,Encoder 为文档向量表征编码器。
在检索阶段,首先,将用户的问题用同一文档表征编码器编码;然后,采用特定向量相似度计算方法计 算用户问题表征与向量数据库中向量的相似度;最后,得到相似度排名即为检索结果。该过程如式(2)。
[Score = Similarity left(Vec_{g}, Vec_{n} ight) ag{2}]
其中 为向量相似度计算方法 (Vec) 为用户问题表征向量 (Vec) 为向量库中存储的文本切 片表征向量。
在电力行业领域中,知识存在复杂的语义相似性问题,因此在本文方案中,采用稠密检索索引技术构建 电力行业外部知识库。
外部知识库经过人工的清洗以及初步标注以后,通常被整理成为长度固定的文本切片格式,这些切片 往往长于用户输入的问题。这种长度差异导致它们的语义信息粒度存在不对等现象。在用文档向量表征 编码器提取它们的特征时,这种语义信息粒度的不同会影响表征提取质量,最终使得检索的准确度下降。
为了解决上述问题,本文提出一个基于大语言模型的检索粒度对齐方法来对电力行业外部知识库进行 构建。该方法首先利用大语言模型对行业外部知识文本切片进行问题生成,生成的问题能够被相应切片较 好地回答;然后,构建“问题-文本切片” 映射关系;最后,用得到的问题替代原始切片进行表征向量提取,并 存入向量库。从而,很好地解决检索过程中由于语义信息粒度不对等产生的性能下降的问题。
在检索阶段,只需对用户问题表征向量与向量库中生成问题向量进行相似度计算,然后利用相应映射 关系找到最终的文本切片。
本方案中,采用提示词工程来显式地引导大语言模型完成文 本切片问题生成任务,图2 为提示词示例。其中, < ANSWER > 为文本切片占位符。后续替换成为需要生成问题的文档切片。
你现在的任务是帮助我构造问答对,我给你问题 的答案,你根据答案来生成相关问题,使得该问题 能够被我提供的答案很好地回答。生成的问题要求 精炼,能够突出重点,我给你的答案是: ""。你生成的问题是:
1.2 电力行业文档表征编码器训练方法
电力行业文档表征编码器在电力行业外部知识库构建中起 着重要作用。现有的编码器模型往往是针对通用领域训练的,其 训练数据的特征分布与电力行业数据分布有着较大的差异,因此这些模型无法用于电力行业知识库构建。 为了解决上述问题,本方案提出一个基于负样本挖掘的迭代式电力行业文档表征编码器模型训练方法。该 方法以BERT(Bidirectional Encoder Representation from Transformers)模型 感知的编码器模型,在经过大规模语料的预训练后,其对文本有着较强的特征编码能力。
在数据准备阶段,首先,收集电力行业知识问答对数据;其次,使用大模型进行电力行业数据改写,生成
语义相似但是表达方式不同的平行语料数据;最后,将2 种类型的数据进行混合,得到最终训练数据集。由 于得到的原始数据集只包含正样本对(问题-答案,电力行业文本-改写的电力行业文本),而大量研究表明, 负样本对于表征编码器模型性能的提升有着很大的作用。因此,在本方案中,采用负样本挖掘方法额外对 原始数据集进行增强。负样本挖掘的目的是找到与原始文本类似,但是语义相差较大的样本,通过对比这 些样本与原始文本间的差异,文档表征编码器模型能够学习到如何提取出文本最本质的特征。
因此,采用对比学习的方式训练文档表征编码器模型。对比学习的目的是拉近具有相似语义文本表征 在特征隐空间上的距离,同时扩大非相似文本表征之间的距离。对比学习的损失函数计算方法如式(3)所示。
[mathcal{L}=-log frac{exp left(q cdot frac{k_{+}}{ au} ight)}{sum_{i=0}^{K} exp left(q cdot frac{k_{i}}{ au} ight)} ag{3}]
其中 q 为原始训练样本 (k_{+}) 为原始样本对应的正样本 (k_{i}) 包含正样本以及挖掘出的负样本 τ 为温度值。
本文采用迭代式优化训练方法,在经过上述步骤训练出文档表征编码器模型后,利用该模型进行下一 轮的负样本挖掘,然后继续对模型进行训练。重复上述步骤,直到最终收敛到较优解。
1.3 大模型外部知识融合方法
知识性大语言模型推理的最后一步,是将检索得到的外部知识文本切片与用户原始问题通过提示词工 程转换成输入到大模型的最终文本。经过研究与实验,发现将选取切片本身及与其相邻的上下文组合到一 起后进行提示词构建,最终可以得到较好的效果。该操作在确保模型能够获得所需知识的同时,避免单个 文档切片存在的语义缺失以及语义不完整的问题。
2 实验验证
本节将分别介绍实验的相关设置以及分析最终的实验结果。实验结果证明所提出的电力行业知识性 大语言模型构建方案的有效性。
2.1 数据集介绍
本文使用2 个电力行业内部数据集来验证提出的电力行业文档表征编码器训练方法的有效性。数据集 名称分别为Power-Know 以及Power-Cust。Power-Know 数据集为电力行业知识性问答数据集,包含313 条测 试样本。Power-Cust 数据集为电力行业客服问答数据集,包含182 条测试数据。Power-Cust 数据集相较于编 码器模型的训练数据集具有一定的分布偏移,因此实验中使用该数据集来测试验证模型的泛化能力。
本文使用标准的信息检索评价指标召回率来衡量文档表征向量编码器模型的表现。召回率的表达方 式为代表在文档编码模型计算出的前 N 个最相似的文档中包含正确答案的比率本实验中分 别设置N 值为1,2,5,10 和20。
2.2 大语言模型
在针对整个电力行业知识性大语言模型构建方案的测试中,本文选取开源的Baichuan-13B-Chat 模型
作为基座模型。Baichuan-13B-Chat 为百川智能发布的经过指令对齐的对话大语言模型。该模型采用多头 注意力机制以及ALiBi 位置编码等主流大模型技术,表现出较强的指令遵从以及自然语言理解能力。
2.3 实验环境及训练参数
本文中的实验代码采用Python( 版本号3. 8. 16) 语言实现,采用的深度学习框架为PyTorch( 版本号 2. 0. 0 + cu117)。模型训练过程中使用NVIDIA A800 (80GB-PCIe) 作为训练加速器,训练时间约为2. 5 小 时,学习率设置为6e-5,最大训练轮次设置为10。
3 实验结果以及分析
3.1 文档向量表征编码器模型实验结果以及分析
本实验中,采用BGE 向量编码模型BGE-Vec 以 及重排序模型BGE-Reranker( BGE-Re) [12] 作为基线
模型。BGE 是一个开源的主流编码器模型系列,其 在稠密向量检索领域有着重要的影响。实验结果如 表1 和图3 所示。
表1 文档表征向量编码器实验结果
| 方法 | Power-Know | Power-Cust |
| Recall@ 1-BGE-Vec | 69. 65 | 75. 82 |
| Recll@ 1-BGE-Re | 72. 33 | 80. 07 |
| Recall@ 1-ours | 76 . 68 | 82 . 42 |
| Recall@ 2-BGE-Vec | 80. 19 | 86. 81 |
| Recall@ 2-BGE-Re | 83. 12 | 89. 76 |
| Recall@ 2-ours | 86 . 58 | 91 . 76 |
| Recall@ 5-BGE-Vec | 87. 54 | 95. 05 |
| Recall@ 5-BGE-Re | 89. 23 | 95. 34 |
| Recall@ 5-ours | 93 . 29 | 97 . 25 |
| Recall@ 10-BGE-Vec | 90. 74 | 97. 25 |
| Recall@ 10-BGE-Re | 94. 52 | 97. 67 |
| Recall@ 10-ours | 96 . 81 | 98 . 25 |
| Recall@ 20-BGE-Vec | 92. 65 | 98. 35 |
| Recall@ 20-BGE-Re | 95. 08 | 98. 99 |
| Recall@ 20-ours | 98 . 72 | 100 . 00 |
从表1 以及图3 中的结果可以看出,本文提出的 电力行业文档表征向量编码器模型训练方法可以显 著提升电力行业知识性大模型在外部知识检索阶段 获取相关信息的准确度,使得大模型可以更加专注 于相关信息,减少其被无关噪声的干扰,最终有效提 升大模型的最终表现。
3.2 电力行业知识性大语言模型实验结果以及分析
对电力行业知识性大语言模型的效果做了实验 测试。以电力行业专业问题为测试案例,对比原始 大模型以及通过本文提出的方案构建的大模型的回 答效果,结果如图4 所示。
通过分析图4 中的实验结果,可以发现,原始大语言模型在回答电力行业专业问题时,由于缺少相关专 业知识,会融合存储在其参数内部的知识生成一个看似正确,但是缺乏实际依据的错误答案。而本文提出 的电力行业知识性大模型,能够实时结合外部行业知识库,对问题进行答案的精准生成。
4 结束语
本文针对大语言模型存在“幻觉” 现象,导致在垂直领域无法取得较好应用表现的问题,以电力行业为 例,提出一套完整的电力行业知识性大语言模型构建方案。该方案包含电力行业外部知识库构建,电力行 业文档表征编码器训练以及大模型外部知识融合3 种方法。实验结果验证提出的方法的有效性,为后续垂 直行业知识性大模型的构建提供了思路。
参考文献
[1] Wu T, He S, Liu J, et al. A Brief Overview of ChatGPT: The History, Status Quo and Potential Future Development[J]. IEEE / CAA Journal of Automatica Sinica, 2023, 10(5): 1122-1136.
[2] Huang L, Yu W, Ma W, et al. A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions[EB/OL]. arXiv preprint arXiv:2311. 05232. (2023-11-09)[2024-11-08].
[3] Rawte V, Sheth A, Das A. A Survey of Hallucination in Large Foundation Models [EB/OL]. arXiv preprint arXiv:2309. 05922. (2023-09-12)[2024-11-08].
[4] Tonmoy S M, Zaman S M, Jain V, et al. A Comprehensive Survey of Hallucination Mitigation Techniques in Large Language Models [EB/OL]. arXiv preprint arXiv:2401. 01313. (2024-01-08)[2024-11-08].
[5] Fan W, Ding Y, Ning L, et al. A Survey on Rag Meeting LLMs: Towards Retrieval-Augmented Generation[C]//Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 2024: 6491-6501.
[6] Gao Y, Xiong Y, Gao X, et al. Retrieval-Augmented Generation for Large Language Models: A Survey[EB/OL]. arXiv preprint arXiv:2312. 10997. (2024-03-27)[2024-11-08].
[7] Gupta S, Ranjan R, Singh S N. A Comprehensive Survey of Retrieval-Augmented Generation (RAG): Evolution, Current Landscape and Future Directions [EB/OL]. arXiv preprint arXiv:2410. 12837. (2024-10-03)[2024-11-08].
[8] Formal T, Lassance C, Piwowarski B, et al. SPLADE v2: Sparse Lexical and Expansion Model for Information Retrieval [EB/OL]. arXiv preprint arXiv:2109. 10086. (2021-09-21)[2024-11-08].
[9] Zhao W X, Liu J, Ren R, et al. Dense Text Retrieval Based on Pretrained Language Models[J]. ACM Transactions on Information Systems, 2024, 42(4): 1-60.
[10] Robertson S, Zaragoza H. The Probabilistic Relevance Framework: BM25 and Beyond[J]. Foundations and Trends in Information Retrieval, 2009, 3(4): 333-389.
[11] Devlin J. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[EB/OL]. arXiv preprint arXiv: 1810. 04805. (2021-05-24)[2024-11-08].
[12] Xiao S, Liu Z, Zhang P, et al. C-pack: Packaged Resources to Advance General Chinese Embedding[EB/OL]. arXiv preprint arXiv:2309. 07597. (2021-09-24)[2024-11-08].
转载请注明来自:http://www.lunwencheng.com/lunwen/dzi/22784.html
