摘 要: 针对全景驾驶感知算法YOLOP存在特征图池化操作自适应较差、下采样过程细节丢失和模型性能差的问题,提出一种基于多任务学习的全景驾驶感知算法,引入高效处理模块,提高对特征图池化操作自适应能力,采用不同加权系数的损失函数,提升网络的检测性能及鲁棒性。在BDD100K数据集的评估结果中,车道线检测准确率提高11.6%,可行驶区域检测的平均交并比(mIoU)提高2.1%,车辆检测的平均精确率均值的50%指标(mAP50)提高3.7%。在KITTI数据集的评估结果中,车辆检测mAP50指标提高3.4%。
关键词: 多任务学习网络;编码‑解码器;车道线检测;可行驶区域检测;车辆检测;特征对齐;转置卷积
论文《基于多任务学习的全景驾驶感知算法》发表在《计算机工程与设计》,版权归《计算机工程与设计》所有。本文来自网络平台,仅供参考。
0 引 言
随着5G时代的到来,智能网联汽车迅速发展,全景驾驶感知系统作为其关键部分之一,也在持续发展。随着深度学习技术的发展,全景驾驶感知技术也在不断进步。在车道线检测领域,采用LaneATT、ENet(efficient net)、SCNN(spatial convolutional neural network)等深度学习算法,实现更精确的车道线检测。在可行驶区域检测领域采用PSPNet(pyramid scene parsing network)、DeepLabv3+等多尺度算法,有效提高可行驶区域检测的准确性与鲁棒性;在车辆检测领域,一些深度学习模型逐渐替代传统的车辆检测方法,包括Faster R‑CNN(region‑based convolutional neural network)、SSD(single shot multibox detector)等。目前主流的目标检测算法如YOLOv5(you only look once version 5)、YOLOv8等,为多任务学习网络提供了思路。
尽管每个任务单独达到了良好的性能,但在多任务结合时往往难以平衡各方面需求。研究者们提出了一系列多任务学习网络如DLT‑Net、MultiNet、YOLOP、HybridNets、YOLOPv2等,将单一任务整合为多任务,并通过同时处理来获得更好的性能。
全景驾驶感知算法YOLOP作为早期处理多任务交通场景的模型之一,存在多任务特征图池化操作适应性差和下采样过程丢失细节的问题。因此,本文提出一种基于多任务学习的全景驾驶感知算法,通过优化网络结构和引入轻量化模块,在保证模型参数较小的情况下,提高检测性能,并确保与YOLOP网络推理速度相当,有效解决适应性差和细节丢失的问题。
1 多任务学习网络
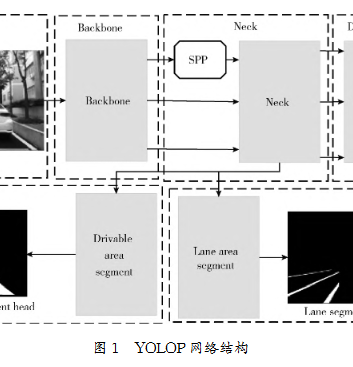
YOLOP作为一个常用于交通场景的多任务网络,其主要由一个编码器和3个解码器组成,其网络结构如图1所示。
编码器部分由一个Backbone网络和一个Neck网络组成,并使用CSPDarknet(cross stage partial dark‑net)网络作为Backbone网络,而Neck网络则由SPP(spatial pyramid pooling)与FPN(feature pyramid network)组成。解码器部分则由车辆检测头、可行驶区域分割头和车道线检测头组成,通过一系列的卷积层和BottleneckCSP模块实现可行驶区域和车道线的检测。最后将预测结果分为多个尺度,以此提高检测精度。
整个YOLOP网络结构允许从端到端的训练,可直接输入图像并在输出中得到3个任务的结果。除了端到端的训练策略,还采用了一些交替优化范式。尽管这种范式有时会更加复杂,但它在实验中表现出良好的效果。
2 改进YOLOP算法
本文的多任务学习算法网络结构如图2所示。在YOLOP网络结构的基础上引入C2f结构,加快模型的训练以及推理速度,引入SPPF有效解决特征图池化操作自适应问题,引入转置卷积有效解决细节丢失问题。同时,优化了部分网络层,并减小部分卷积核大小,降低计算复杂度,从而提高模型的训练和推理速度。
2.1 改进网络结构
2.1.1 C2f模块
在改进的网络架构中,BottleneckCSP模块被C2f模块所代替,通过降低通道数的方式显著减少计算量,加快模型的训练和推理速度,并且有效降低显存的使用。通过优化部分网络结构,去掉重复和不必要的计算,进一步减小模型参数和计算量,同时保持模型的准确性和有效性。
2.1.2 SPPF模块
在改进的网络中,SPP模块被更高效的SPPF模块所取代,SPPF模块能够自适应地对特征图进行不同层次大小的池化操作,确保提取到多尺度特征信息。此外,SPPF模块具有更强的信息融合能力,能够熟练地整合多尺度数据,从而增强模型性能。
2.1.3 转置卷积模块
在车道线检测分支中,上采样被转置卷积所取代。与上采样不同,转置卷积将卷积和上采样操作结合在一起,简化了过程。转置卷积根据任务特定要求,利用可修改的卷积核参数,产生更优的结果,增强对细粒度特征的恢复能力,从而提高对车道线边界的感知和分割质量。
2.2 优化多任务学习网络
2.2.1 引入特征对齐网络
(1)在原有的FPN基础上,增加特征对齐网络,通过对不同尺度特征图像中的像素进行对齐,使得不同尺度特征图像的像素数目相等,便于后续的处理。
(2)将可行驶区域检测模块添加到FPN之前,以便更好地利用这些多尺度特征,还可将低分辨率的特征图恢复到原始输入图像的分辨率,并与其它尺度的特征进行融合,更准确地检测出可行驶区域。
(3)在FPN之后接入车道线检测模块,避免对低层特征的过多计算,可提高计算效率,使车道线的信息在得到更高层次的特征提取和融合后更加清晰,进一步提高车道线检测结果的准确性。
2.2.2 优化网络结构
(1)去除Neck层的两个卷积连接层,减少了模型的参数量和计算量,从而降低训练和推理过程的时间和资源消耗,降低特征图的分辨率和卷积的计算复杂度,有效提高特征图上分割头部的分辨率和精度。
(2)在可行驶区域检测分支中增加一个上采样层,通过引入更多的下采样层,更好地捕捉行驶区域边界的细节,提高检测结果的准确性。通过精减模型参数,使模型的速度和稳定性得到全面的提升。
2.3 改进损失函数
在训练过程中,采用不同的损失函数与训练策略,同时将所有任务的损失函数进行加权求和,以实现多个任务的联合学习。
总损失函数加权求和如下所示
[L_{sum}=alpha_{1} L_{det}+alpha_{2} L_{da\_seg}+alpha_{3} L_{lane\_seg}+alpha_{4} L_{line\_ion} quad (1)]
式中:(L_{sum})、(L_{det})、(L_{da\_seg})、(L_{lane\_seg})、(L_{line\_ion})分别为总损失、车辆检测、可行驶区域分割、车道线分割和车道线检测损失函数;(alpha_{1})、(alpha_{2})、(alpha_{3})、(alpha_{4})为各损失函数的权重,(alpha_{2})、(alpha_{3})在原来0.2的基础上调整为0.3和0.5,以增强对细节的关注度,(alpha_{1})、(alpha_{4})保持不变,即分别设置为1和0.2。
车辆检测的损失函数加权求和如下所示
[L_{des}=alpha_{5} L_{box}+alpha_{6} L_{obj}+alpha_{7} L_{cls} quad (2)]
式中:(L_{box})、(L_{obj})、(L_{cls})分别为边界框回归、物体置信度和分类损失函数;(alpha_{5})、(alpha_{6})、(alpha_{7})为各损失函数的权重,与YOLOP保持一致,分别设置为0.05、1.0、0.5,为了提升车辆检测的性能,(L_{obj})、(L_{cls})使用焦点损失函数(focal loss)。
为进一步优化多任务学习网络中车道线检测的性能,采用结合焦点损失函数与DiceLoss的组合损失函数进行模型训练。DiceLoss和焦点损失函数分别针对车道线形状、颜色多样以及经常被遮挡等因素的影响,强调车道线像素的检测,以提高模型对车道线的关注度,同时对训练数据集中存在大量背景像素的问题进行优化。
焦点损失函数与DiceLoss的组合损失函数如下所示
[L_{line\_seg}=L_{Focal}+lambda L_{Dice} quad (3)]
式中:(lambda)为权重系数,将(lambda)设置为2,通过增加DiceLoss的权重,使模型能够更准确地预测车道线,从而提高整体性能。
[L_{Focal}=FL(p_{t})=-alpha_{8}(1-p_{t})^{gamma}ln(p_{t}) quad (4)]
式中:(alpha_{8})为平衡因子,(gamma)为调整因子,(p_{t})为预测概率,(ln(p_{t}))为预测值对数。将(alpha_{8})设置为避免模型过度关注数量较多的负样本,而将(gamma)设置为放大难例样本的权重,使模型更专注于难以分类的样本,进而提升模型的性能。
[L_{Dice}=Dice(y,hat{y})=frac{2|ycaphat{y}|}{|y|+|hat{y}|} quad (5)]
式中:(y)和(hat{y})分别表示真实标签和模型预测标签的二进制掩膜。
3 实 验
3.1 数据集与实验设置
所涉及的实验均基于公开的BDD100K数据集进行,实验采用7:2:1的划分比例来分别构建训练集、测试集和验证集,以确保实验结果具有充分的可靠性和可重复性。
实验均在RTX3090 24G显卡的环境下,使用PyTorch 1.9.0的深度学习框架进行实现。在模型训练过程中,采用余弦退火策略进行学习率的调整,同时使用ADAM优化器,并将初始学习率设置为0.001、最终学习率的倍率因子设置为0.01。在训练过程中进行200次迭代,batch size设置为32,迭代一次的时间约32min。
3.2 评估指标
实验结果性能的评估指标主要有mAP50、召回率、平均交并比(mIoU)、准确率和交并比(IoU),其中mAP50和召回率为车辆检测评估指标,mIoU为可行驶区域检测评估指标,准确率和IoU则为车道线检测评估指标,计算公式如下
[mAP50=AP50=sum_{n}(R_{n}-R_{n-1})P_{n}(IOU=0.5) quad (6)]
[召回率=frac{TP}{TP+FN} quad (7)]
[mIoU=frac{1}{k+1}sum_{i=0}^{k}frac{TP}{FN+FP+TP} quad (8)]
[准确率=frac{TP+TN}{TP+TN+FP+FN} quad (9)]
[IoU=frac{TP}{FN+FP+TP} quad (10)]
其中:(P_{n})和(R_{n})为第(n)个阈值处的预测率和召回率,(R_{n})和(R_{n-1})分别为两个相邻但不相等的区间,(TP)为将车辆像素预测为车辆的像素数,(FN)为将车辆像素预测为背景像素的像素数,(FP)为将背景像素误检为车辆的像素数,(k)为样本的数量,(TN)为预测负样本且与真实标注一致的值。
3.3 实验结果分析
3.3.1 模型性能分析
实验针对4个不同模型在多任务处理上的性能进行对比,其对比情况见表1。其中,研究提出的多任务模型在参数量仅比YOLOP模型多3.1M。但在多项关键指标上,包括召回率、mIoU和准确率等指标均超越YOLOP模型,且性能比基于Transformer模型的WenjieZhu等和YOLOODL模型出色。改进后的模型在速度上也优于HybridNets和YOLOPv2模型,与YOLOP模型相当,可更加精确、快速地处理多项任务,同时占用的计算资源也较少。
表1 不同模型性能实验结果
| 模型 | 参数量/M | mAP50/% | 召回率/% | mIoU/% | 准确率/% | IoU/% | 推理速度/ms |
| YOLOP | 7.9 | 76.5 | 89.2 | 91.5 | 70.5 | 26.2 | 17.4 |
| HybridNets | 12.8 | 77.3 | 92.8 | 90.5 | 85.4 | 31.6 | 61.4 |
| YOLOPv2 | 38.9 | 83.4 | 91.1 | 93.2 | 87.3 | 27.2 | 20.6 |
| WenjieZhu | 8.3 | 75.8 | 89.1 | 91.9 | 74.9 | 27.7 | — |
| YOLO‑ODL | 22.2 | 79.7 | 94.2 | 92.3 | 75.0 | 27.5 | — |
| Ours | 11.0 | 80.2 | 91.3 | 93.6 | 82.1 | 27.5 | 18.0 |
3.3.2 车辆检测结果分析
为增加训练数据的多样性,在处理数据集时,将交通对象合并为单一的汽车类别,以提高车辆检测的准确性和鲁棒性。车辆检测结果见表2,结果表明,改进后的模型相对于传统的多任务检测模型MultiNet,mAP50指标提高20.0%,相比单任务模型YOLOv5s提升3.0%且比Wenjie zhu提升4.4%。
表2 车辆检测实验结果
| 模型 | mAP50/% | 召回率/% |
| MultiNet* | 60.2 | 81.3 |
| DLT‑Net* | 68.4 | 89.4 |
| FasterR‑CNN | 55.6 | 77.2 |
| YOLOv5s | 77.2 | 86.8 |
| YOLOP* | 76.5 | 89.2 |
| HybridNets* | 77.3 | 92.8 |
| YOLOPv2* | 83.4 | 91.1 |
| Wenjiezhu* | 75.8 | 89.1 |
| YOLO‑ODL* | 79.7 | 94.2 |
| Ours* | 80.2 | 91.3 |
注:*为多任务。
3.3.3 可行驶区域检测结果分析
可行驶区域检测模型实验结果对比情况见表3,结果表明,对比多任务模型DLT‑Net提升22.3%,对比单任务模型PSPNet提升4.0%,展现出出色的检测性能。综上所述,改进后的模型在可行驶区域检测任务中展现出卓越的性能。
表3 可行驶区域检测实验结果
| 模型 | mIoU/% |
| MultiNet* | 71.6 |
| DLT‑Net* | 71.3 |
| PSPNet | 89.6 |
| YOLOP* | 91.5 |
| HybridNets* | 90.5 |
| YOLOPv2* | 93.2 |
| WenjieZhu* | 91.9 |
| YOLO‑ODL* | 92.3 |
| Ours* | 93.6 |
注:*为多任务。
3.3.4 车道线检测结果分析
车道线检测实验结果对比情况见表4,结果表明,对比单任务模型ENet模型性能提升将近48%,对比Wenjie Zhu提升了7.2%。比HybridNets与YOLOPv2模型的参数量分别减少了1.8M和27.9M,且推理速度均优于两者。因此可得出结论:改进后的模型相对较小,其在车道线检测方面具有出色的性能,能够在一些边缘设备上实现本地化处理,并表现出较好的精度与细节捕捉能力。
表4 车道线检测实验结果
| 模型 | 准确率/% | IoU/% |
| ENet | 34.12 | 14.64 |
| SCNN | 35.79 | 15.84 |
| ENet‑SAD | 36.56 | 16.02 |
| YOLOP* | 70.50 | 26.20 |
| HybridNets* | 85.40 | 31.60 |
| YOLOPv2* | 87.31 | 27.25 |
| WenjieZhu* | 74.90 | 27.70 |
| YOLO‑ODL* | 75.00 | 27.50 |
| Ours* | 82.10 | 27.50 |
注:*为多任务。
3.3.5 消融实验
通过定量和定性对比实验,改进后的多任务模型与YOLOP模型相比,在各种性能指标上均有显著提升,消融实验结果对比见表5。实验结果表明,本文所提出的优化策略和改进措施确实能够有效地提高模型性能,从而更好地适应实际任务需求。
表5 消融实验结果
| 训练方法 | mAP50/% | 召回率/% | mIoU/% | 准确率/% | IoU/% |
| YOLOP (Baseline) | 76.5 | 89.2 | 91.5 | 70.5 | 26.2 |
| Backbone+Fine‑tuned | 78.1 | 89.6 | 92.0 | 75.4 | 27.6 |
| Diceloss | 77.8 | 89.1 | 92.3 | 79.4 | 27.1 |
| Focalloss+Diceloss | 79.8 | 90.7 | 92.8 | 81.5 | 27.6 |
| 转置卷积 | 80.2 | 91.3 | 93.6 | 82.1 | 27.5 |
总损失曲线如图5所示,消融实验总损失曲线收敛,验证了改进方法的有效性,不会造成过拟合。图5的结果表明,改进后的总损失值较改进前更小,收敛速度更快,进一步证明了改进方法的可行性。
3.4 KITTI数据集结果分析
实验使用KITTI数据集进行模型泛化性的验证,数据集中的图像为7481张,数据划分比例为7.5:1.5,实验仅改变数据集的划分比例,其余设置与前述实验保持一致,实验结果见表6。
表6 KITTI数据集实验结果
| 模型 | 参数量/M | 预测率/% | 召回率/% | mAP50/% | 迭代时间/s |
| YOLOP | 6.8 | 91.5 | 81.9 | 91.2 | 138.0 |
| Ours | 4.7 | 94.3 | 85.6 | 94.6 | 36.3 |
由表6的实验结果可知,研究所提出的算法模型在目标检测性能比YOLOP优越,参数量减少了2.1M,模型训练时间提升了3.8倍,各项评估指标均优于YOLOP模型。因此,KITTI数据集的训练结果充分验证了所提出多任务学习网络的泛化性与优越性。
3.5 可视化结果分析
图6展示了实验结果的可视化对比,通过图6可看出,在车道线和可行驶区域检测方面,改进后的模型优于YOLOP和HybridNets模型,并且在车道线检测的鲁棒性比YOLOPv2好,在车辆检测方面,HybridNets和YOLOPv2模型误检率较高。因此,可以得出结论:改进后的模型在性能表现上优于大多数已有模型,同时具备高鲁棒性和准确度。
4 结束语
本文提出一种基于多任务学习的全景驾驶感知算法,有效解决YOLOP算法整体性能较差、特征图池化操作自适应较差和下采样过程细节丢失问题。该算法不仅在BDD100K数据集上具有出色的检测性能,在KITTI数据集上也能有优越的表现,具备高准确性和鲁棒性。由于显卡算力原因,最终在某些性能的表现略逊于YOLOPv2模型,但从模型参数量和模型推理速度的角度来看,改进后的模型表现更加出色。在下一步研究中,将继续优化网络结构,提高感知准确性,并将其最终整合到现实世界的自动驾驶生态系统中。
参考文献:
[1] Tabelini L,Berriel R,Paixao T M,et al. Keep your eyes on the lane:Real‑time attention‑guided lane detection [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition,2021:294‑302.
[2] Li B,Zhao Y,Lou L. Fast lane detection based on improved enet for driverless cars [C]//Advances in Computational Intelligence Systems:Contributions Presented at the 20th UK Workshop on Computational Intelligence. Springer International Publishing,2022:379‑389.
[3] Zheng T,Fang H,Zhang Y,et al. Resa:Recurrent feature shift aggregator for lane detection [C]//Proceedings of the AAAI Conference on Artificial Intelligence,2021:3547‑3554.
[4] Lv Z,Huang X,Liang Y,et al. An improved efficient model for structure‑aware lane detection of unmanned vehicles [J]. Proceedings of the Institution of Mechanical Engineers,Part D:Journal of Automobile Engineering,2021,235(9):2496‑2508.
[5] Baheti B,Innani S,Gajre S,et al. Semantic scene segmentation in unstructured environment with modified DeepLabV3+ [J]. Pattern Recognition Letters,2020,138:223‑223.
[6] Wan S,Goudos S. Faster R‑CNN for multi‑class fruit detection using a robotic vision system [J]. Computer Networks,2020,168:107036.1‑107036.6.
[7] 李国进,胡洁,艾矫燕. 基于改进SSD算法的车辆检测[J]. 计算机工程,2022,48(1):266‑274.
[8] 王鹏,王玉林,焦博文,等. 基于YOLOv5的道路目标检测算法研究[J]. 计算机工程与应用,2023,59(1):117‑125.
[9] Kim J H,Kim N,Won C S. High‑speed dron detection based on Yolo‑V8 [C]//IEEE International Conference on Acoustics,Speech and Signal Processing. IEEE,2023:1‑2.
[10] Qian Y,Dolan J M,Yang M. DLT‑Net:Joint detection of drivable areas,lane lines,and traffic objects [J]. IEEE Transactions on Intelligent Transportation Systems,2019,21(11):4670‑4679.
[11] Khan S I,Shahrior A,Karim R,et al. MultiNet:A deep neural network approach for detecting breast cancer through multi‑scale feature fusion [J]. Journal of King Saud University Computer and Information Sciences,2022,34(8):6217‑6228.
[12] Wu D,Liao M,Zhang W,et al. YOLOP:You only look once for panoptic driving perception [J]. Machine Intelligence Research,2022,19(6):550‑562.
[13] Vu D,Ngo B,Phan H. Hybridnets:End‑to‑end perception network [EB/OL]. [2024‑04‑21]. https://doi.org/10.48550/arXiv.2203.09035.
[14] Han C,Zhao Q,Zhang S,et al. YOLOPv2:Better,faster,stronger for panoptic driving perception [EB/OL]. [2024‑04‑21]. https://doi.org/10.48550/arXiv.2208.11434.
[15] Wang G,Chen Y,An P,et al. UAV‑YOLOv8:A small object‑detection model based on improved YOLOv8 for UAV aerial photography scenarios [J]. Sensors,2023,23(16):7190‑7217.
[16] Tang H,Liang S,Yao D,et al. A visual defect detection for optics lens based on the YOLOv5‑C3CA‑SPPF network model [J]. Optics Express,2023,31(2):2628‑2643.
[17] Weng W,Zhu X. INet:Convolutional networks for biomedical image segmentation [J]. IEEE Access,2021,9:16591‑16603.
[18] Zhou L,Rao X,Li Y,et al. A lightweight object detection method in aerial images based on dense feature fusion path aggregation network [J]. ISPRS International Journal of Geo‑Information,2022,11(3):189‑213.
[19] Chen M,Fang L,Liu H. FR‑NET:Focal loss constrained deep residual networks for segmentation of cardiac MRI [C]//IEEE 16th International Symposium on Biomedical Imaging. IEEE,2019:764‑767.
[20] Cui Y,Jia M,Lin T Y,et al. Class‑balanced loss based on effective number of samples [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition,2019:9268‑9277.
[21] Gan X,Qu J,Yin J,et al. Road damage detection and classification based on M2det [C]//Proceedings Advances in Artificial Intelligence and Security:7th International Conference. Springer International Publishing,2021:429‑440.
[22] Zhu W,Li H,Cheng X,et al. A multi‑task road feature extraction network with grouped convolution and attention mechanisms [J]. Sensors,2023,23(19):8182‑8196.
[23] Guo J,Wang J,Wang H,et al. Research on road scene understanding of autonomous vehicles based on multi‑task learning [J]. Sensors,2023,23(13):6238‑6252.
转载请注明来自:http://www.lunwencheng.com/lunwen/dzi/22773.html
